Harvesting Tweets for Data Visualisation
The Brock University Digital Scholarship Lab has implemented use of the Twitter Archive (TWARC). TWARC is a command line based Twitter harvesting script that is one of many tools available as part of the Digital Scholarship Lab’s Research Tools On Demand (RTOD). TWARC can harvest tweets based on keywords in two main ways; search and filter.
Search
The search tool in TWARC can look at every tweet from the last seven days and harvest each one that matches with your keywords. This is great for quickly understanding the latest trends pertaining to a topic.
Filter
The filter tool in TWARC is an active filter that captures any tweet that matches one of your keywords as it happens. This is excellent if there is an event that spans a few hours or days that you want to gather data on. It can also be used to get an idea of how active a topic is within windows of minutes, hours, days, or even months.
Our Example
At the DSL we are big fans of data visualization so we set TWARC to harvest all tweets that included the keyword “datavisualization” for twenty-four hours. This produced a file containing over four-hundred tweets!
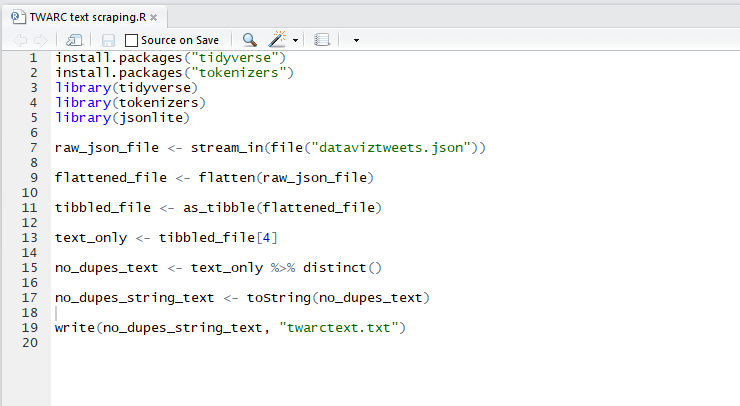
We then used the R programming language to remove duplicate tweets (there were quite a few) and strip away the extra metadata that came with the tweets so that we could perform text analysis on them.
Once we had a clean text file to work with we uploaded it to Voyant (try out Voyant here) and used a curated list of stopwords to create a wordcloud out of our tweets showing the fourty-five most commonly used words.

We have provided all of the data that was used in this example here so that you can run through the analysis yoursel if you would like! Included is:
- The original .json file that was produced by TWARC
- A Jupyter Notebook containing the R code used to clean the data
- The text file produced by the R scripts
- A stopword list formatted for use in Voyant
Contact Us
Do you have a project that would benefit from harvesting twitter data using TWARC? We can help you with that!
Do you have a corpus of textual data that you would like to do some analysis on? Try out Voyant or go to our Eventbrite page and look for our next “R for Text Analysis” workshop and sign up!
For other ideas, or help on your projects, come visit us in the Rankin Family Pavilion at Brock University or e-mail us at DSL@Brocku.ca.
![]()