
Text Analysis with R
In this workshop you will learn about the basics of doing text analysis with the R programming language. This includes:
- Tokenizing a corpus of text
- Learning about stopwords and how to deal with them
- Learning the basics of doing word frequency analysis
A basic understanding of the R programming language is recommended for this workshop.
Estimated workshop length: 2 hours
Setup Instructions
In preparation for this workshop, you will need to have a Posit account (previously was an R Studio Cloud account) and have a new R Studio project open on Posit Cloud. Follow the steps below to get set up.
- (Skip this step if you already have an Posit account) Begin by going to https://posit.cloud/ and signing up for an account by clicking on the “Sign Up” text at the top right of the screen, then click the grey “Sign Up” button and fill in the form (or use the convenient Google or GitHub options if you have one of those accounts)
- Log in to Posit
- You should arrive at your workspace. From here click on the button that says, “New Project” and select “New R Studio Project”
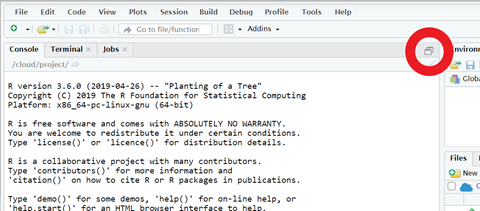
- Once your project has finished building, open the “Source” window by clicking on the double box symbol in the top right corner of the “Console” window
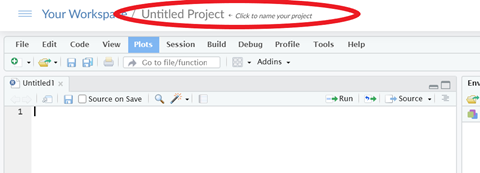
- Rename your project by clicking on the name at the top. Name it whatever you like (eg. “R for Text Analysis Workshop”)
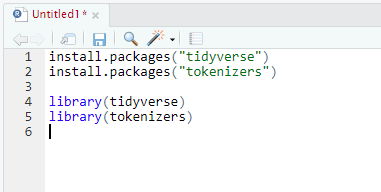
- Lastly, install and activate both the “tidyverse” and “tokenizers” packages. This may take a couple of minutes. Make sure to wait until one is completed before running the next.
install.packages("tidyverse")
install.packages("tokenizers")
library(tidyverse)
library(tokenizers)
- And thats it! You are all set for the workshop
Workshop Tasks
Task Set #1
-
Create a variable called “text” using the following code:
text <- paste("You will rejoice to hear that no disaster has accompanied the commencement of an enterprise which you have regarded with such evil forebodings. I arrived here yesterday, and my first task is to assure my dear sister of my welfare and increasing confidence in the success of my undertaking") - Create a variable containing the above text tokenized into words (Remember that the tokenizer makes a list of lists)
- Find out how long your new list of words is using the length function
- Turn your list of words into a data frame (remember to make it into a table first)
- Arrange your data frame so the most common words are listed first
- When you are done type “GOT IT!!” into the chat
Task Set #2
- Tokenize the paragraph in the “text” variable into sentences and pull out just the list
- Tokenize your sentences into lists of words
- Use the “sapply” function to find the length of each list of words
- When you are done type “TOKENIZED!!” into the chat
Task Set #3
-
Use the code below to load in the full text of the book “Frankenstein”
text <- paste(readLines("https://raw.githubusercontent.com/BrockDSL/R_for_Text_Analysis/master/frankenstein.txt"),collapse = "\n") - Using your code from before, tokenize the book into words and then turn it into a dataframe arranged by count
-
Use the code below to load in the word frequency dataset
wordfreq <- read_csv("https://raw.githubusercontent.com/BrockDSL/R_for_Text_Analysis/master/wordfrequency.csv") - Join the two datasets together to get frequency values for each word in the book
- Filter your results to remove the stopwords. (Try out different frequency values to see more or less common words)
- Type “STOPWORDS ELIMINATED” into the chat when you are done
Task Set 4
- Make a function that takes in a variable containing text and outputs a dataframe filtered to remove stopwords.
- Try out your new function by running on the text variable.
-
(optional) Try out the function on some of these other books using the code below to build the variables.
dracula_text <- paste(readLines("https://raw.githubusercontent.com/BrockDSL/R_for_Text_Analysis/master/dracula.txt"),collapse = "\n")prideandprejudice_text <- paste(readLines("https://raw.githubusercontent.com/BrockDSL/R_for_Text_Analysis/master/prideandprejudice.txt"),collapse = "\n")gatsby_text <- paste(readLines("https://raw.githubusercontent.com/BrockDSL/R_for_Text_Analysis/master/greatgatsby.txt"),collapse = "\n") - When you are done type “TEXT ANALYSIS MASTERED!!!” in the chat.
Follow Up Material
If you are looking to continue enhancing your knowledge of R, check out our other R workshops or try out one of the options below!
YaRrr! The Pirate’s Guide to R
Programming Historians R Text Analysis
This workshop is brought to you by the Brock University Digital Scholarship Lab. For a listing of our upcoming workshops go to Experience BU if you are a Brock affiliate or Eventbrite page for external attendees.