As the analysis of our web archives collected during the pandemic draws to a close, it is time to share some of the work that we have produced. Instead of analysing the entire 300 GB collection of archives, we have primarily relied on a full text extraction of webpages provided by the ARCH service and trained our focus on a select number of URLs. The number of Google Colab notebooks we now have has grown quite a bit, based on questions posed by Dr. Duncan Koerber and we encourage you to see the entire collection on our Github page. Some of the more interesting work has involved sentiment analysis and text similarity determination of web page content. Other quantitative questions have also been examined in the notebooks to assist Dr. Koerber in his close readings of the texts, such as when vaccines were first mentioned and how often they were discussed, and how often page content was updated.
Most of our notebooks rely on popular NLP libraries such as spaCy, scikit-learn, nltk, Gensim, and Flair and make use of Pandas and matplotlib for manipulating data. These libraries, especially when used in conjunction with the Colab platform, allowed us to analyze, display, and share data faster and easier than we would have previously been able to. Technology is progress!
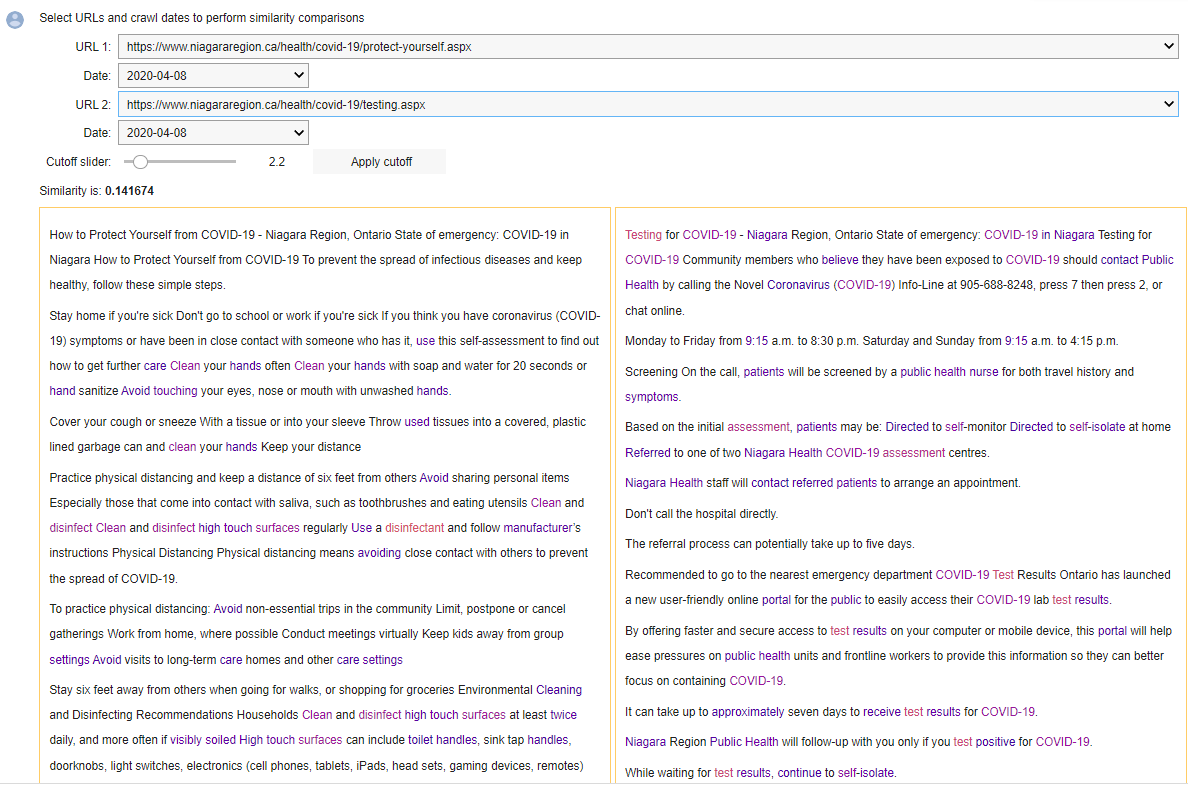
One question that Dr. Koerber posed early on was whether Covid-19 content was similar among the twelve municipalities analyzed. To answer this, we turned to using a technique called TD-IDF. Here is a picture of this in action from our notebook. The user selects two URLs to compare, and a similarity score is generated. Words are coloured based on their contribution towards similarity, with brighter colored words having greater significance.
Dr. Koerber also wished to determine the sentiment of tweets by Pelham’s mayor Marvin Junkin, as well as the sentiment of the different municipal webpages. The data was analyzed using three different methods: two of which were based on human derived lexicon and rules (TextBlob, VADER) and one of which was machine learning based (DistilBert). Unfortunately, each method produced quite different results and we interpreted this in part because of the specific training set and lexicon chosen for the methods. Dr. Koerber then compared his close readings to the results to determine the method he considered most appropriate for our data.
Analyzing the web archives would certainly have been much more challenging if we did not have the ARCH full-text derivatives, the use of Python and its spectacular libraries, and the Google Colab environment. Dealing with duplicated code among our many notebooks, as well as limitations with the Google Colab environment - in comparison to Jupyter-Lab – posed some issues but were positively outweighed by the speed and convenience of using such an environment. Overall, we feel quite lucky to have been chosen as part of the Archives Unleashed 2021 cohort and given the chance to pour over this interesting dataset.
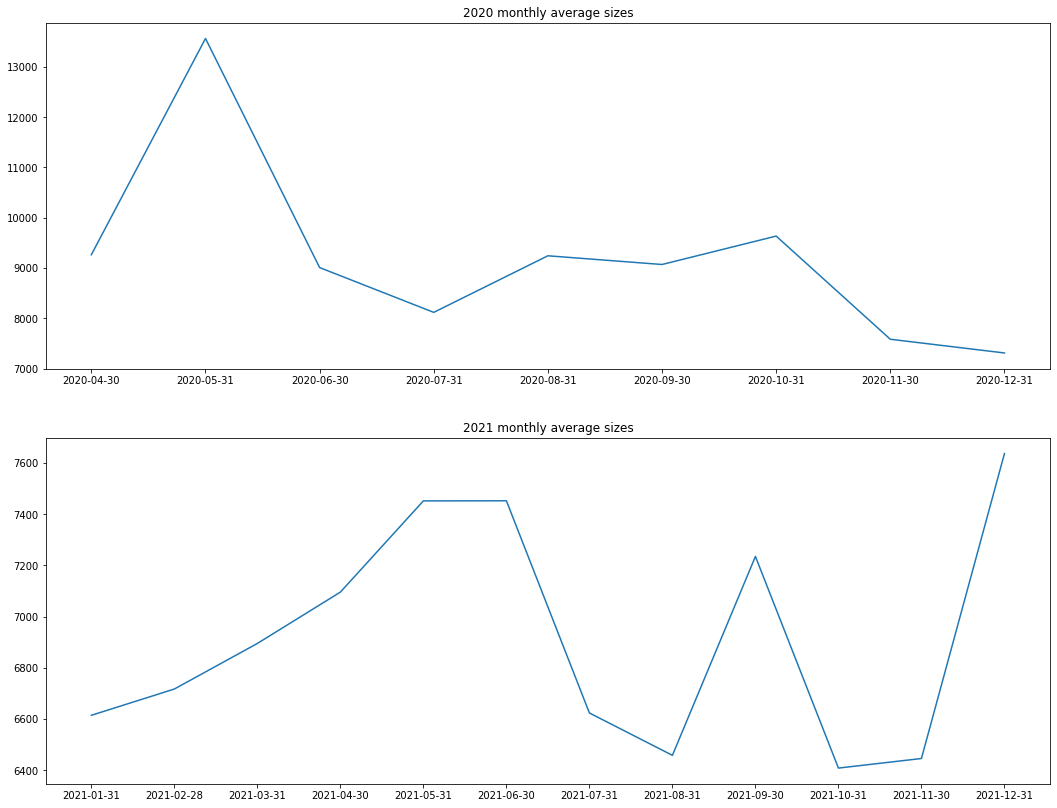
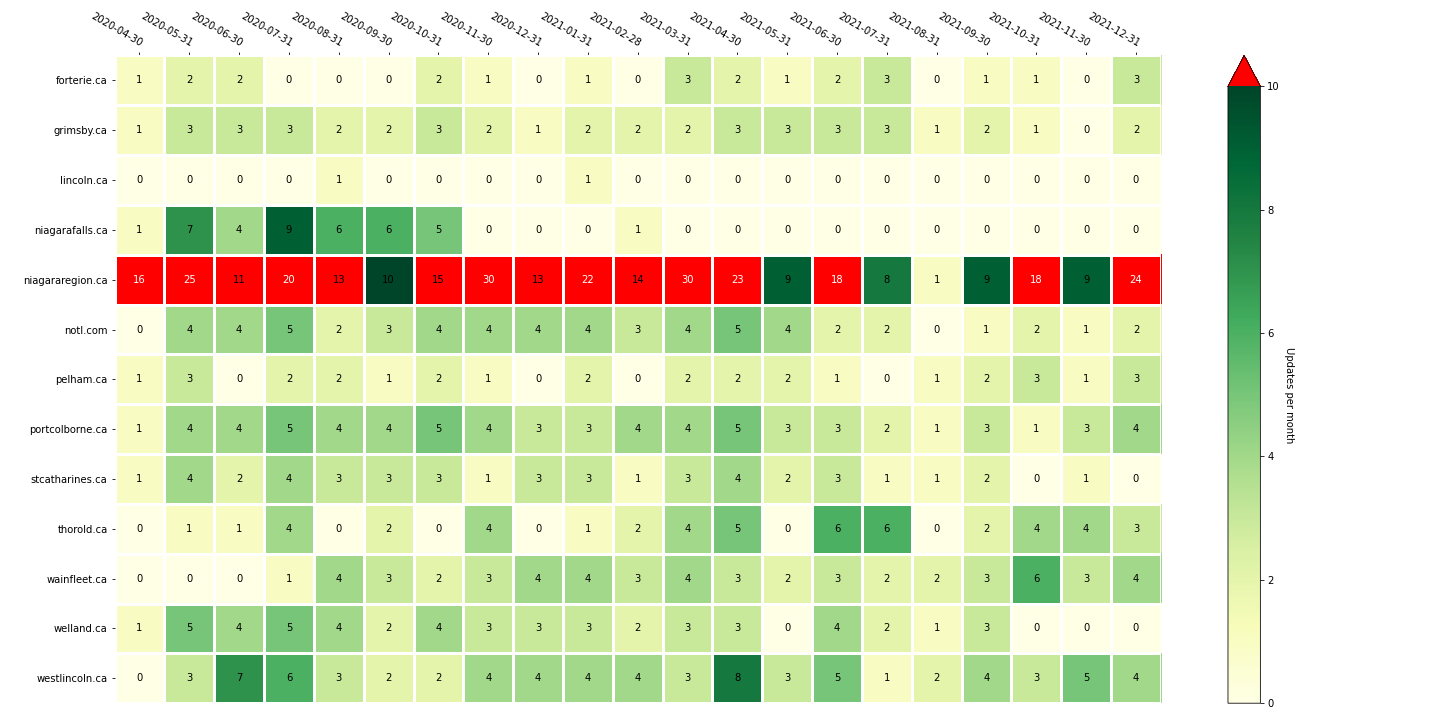
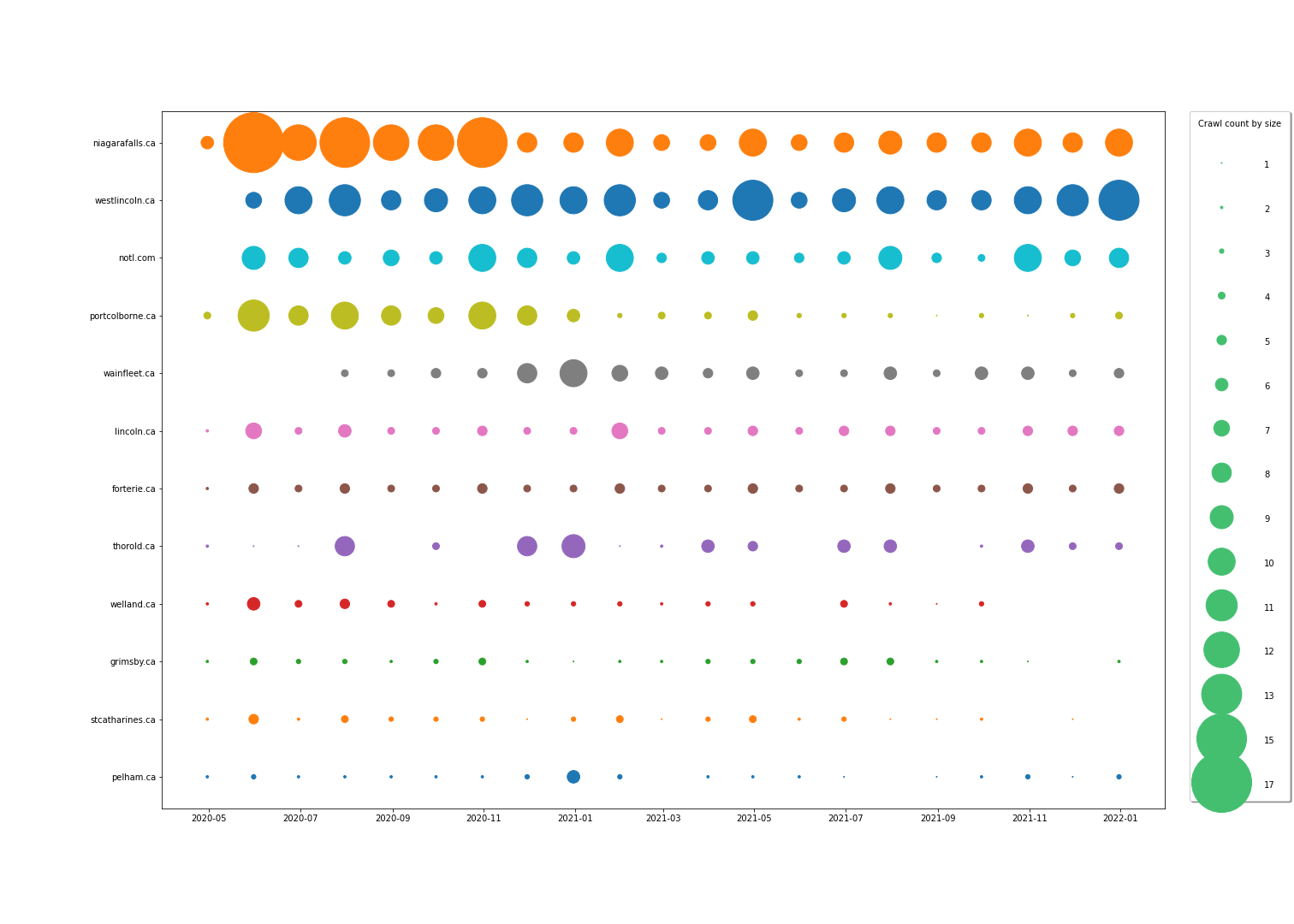
And, here is a sampling of some of the results we have derived and the notebooks in which they are from. Click the image to see it enlarged and click the link to see the notebook in action.