As participants in the Archives Unleashed Cohort Program, our research aims to explore the way Covid-19 has been communicated by municipal governments, businesses, and other organizations in the Niagra region. Exploring the dimensions of crisis communication is a complex undertaking, even more so when numerous actors with varying messages, intentions, motivations, and degrees of style are present. To gain a better understanding of how this communication has occurred, the team will be pouring over 300 GBs of webpages archived during the pandemic.
One tool that we are looking to help explore such a large body of documents is Warclight, a web application and frontend for exploring web archives (WARCs) that have been indexed into Apache Solr. Solr is a powerful engine that allows for the efficient location of documents based on full-text search and facets but is difficult to use without firsthand knowledge of its query language. WARCs are an ISO 28500 standard file format developed to facilitate the archival of web pages. Information stored includes metadata such as the date and time of the request and the HTTP response, while the actual data can be HTML, images, videos, and other types of media. In the context of our own collection, we have tens of thousands of WARCs, which correspond to the “web crawls” of web pages that we are interested in examining. Warclight is necessary because even though technically these WARCs can be indexed into Solr, searching over the collection can be quite cumbersome without a convenient interface.
Our current workflow is as follows: Archive-It! is used to archive web crawls of select websites from the Niagra region. This data is available in WARCs and can be downloaded using an exposed API and py-waspi-client. WARCs are then indexed into Solr using the UK Web Archive’s Web Archive Discovery Tool. Our instance of Warclight is hosted on Amazon AWS and is deployed using Ansible, a tool that makes routine system administrative tasks easier and more reliable. Using virtual machines and Ansible together, ensures that deployments are repeatable and fast. And while the setup of Warclight has been relatively straightforward, estimating the amount of space that will be necessary to index our entire collection of WARCs is still unknown. Nevertheless, it should be less than the total size of our WARC collection. Another open question is how long it will take to index the entirety of our WARCs into Solr from scratch.
Components and services used

Once Warclight has access to indexed WARCs, information discovery occurs in several ways. Facets are very useful for isolating data. Full text search is also useful for locating webpages based on keywords, phrases, or other textual linkages. Once results are found, metadata about an archive can pinpoint a user to further clues, such as when the data was archived, the host that was crawled, outbound links, and a link to a recent archive of the page - accomplished using the Momento Timetravel API.
Available facets
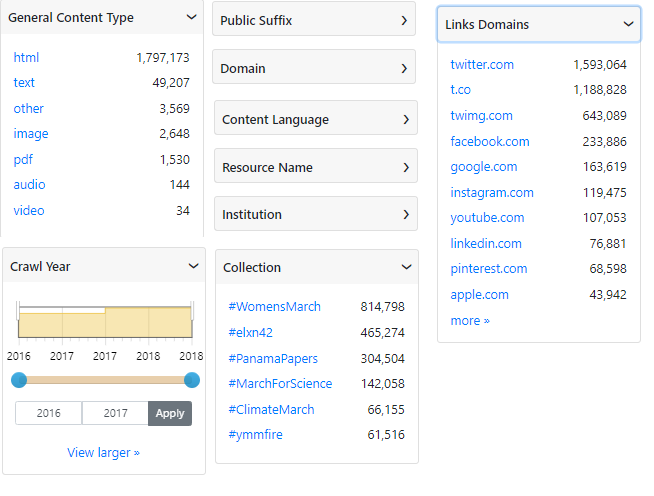
Searching in Warclight
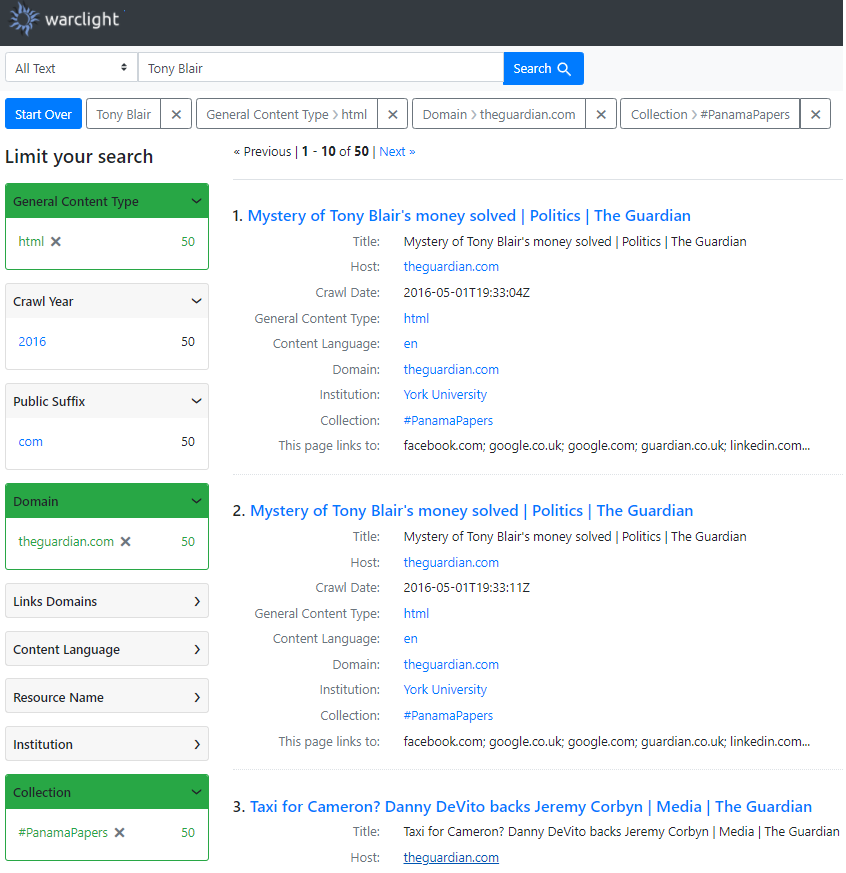
One perceived drawback of Warclight is that it does not have any methods for displaying the captured data, itself. If an image or video is provided as a search result, the user cannot view this media as it was captured and must replay on a Timetravel generated URL. Similarly for HTML data, only the raw extracted text is available, with the layout, images, CSS, and functionality stripped from the results. Here again, a Timetravel URL is used to view the original page. However, it is important to understand the limitations of using the Timetravel service, as it serves up captures created by other organizations, at temporal times closest to – and most importantly, not necessarily exactly – the time that a WARC was generated. This means that there may be at times inconsistencies with the raw data that Warclight shows and the provided web archive URL by the Timetravel service. Given that we have access to the actual WARCs and Warclight provides a reference to the WARC file that generated a search result, this hopefully should not prove to be a real issue.
We hope that Warclight will prove to be a robust and powerful tool for examining our web archives and that it will help use answer questions about how Covid-19 has been communicated within the Niagra region.
About Warclight
Warclight is released by the Archives Unleashed Project and was developed by Nick Ruest from York University Libraries, and Ian Milligan and Jimmy Lin from the University of Waterloo. Warclight in turn is based off Blacklight, a frontend interface for Solr, but adds support for browsing indexed WARC data. An online demo of Warclight is available at https://warclight.archivesunleashed.org/, that has several interesting collections to browse.